Paper Review: Distributed Representations of Words and Phrases and their Compositionality
20 Dec 2018Introduction: 빈칸 추론 문제
영어를 잘하는 사람은 다음 문제를 풀 수 있을 것이다.

자료: 2019년 대학수학능력시험 영어영역
위 문제는 어려운 편에 속하는 빈칸 추론 문제이다. 문맥을 완벽하게 이해하고 다섯 개의 단어도 모두 알아야만 정확하게 풀 수 있기 때문이다.
그러나 많은 경우, 특히 토익에서 나오는 저배점 문제의 경우는 대충 보고도 풀 수 있는 경우가 많다. 특히 해당 언어가 모국어인 경우는 더더욱 그러하다. 다음과 같은 문제를 풀어보자.
나는 ____을 뒤집어 쓰고 펑펑 울었다.
한국어가 모국어이거나, 한국말을 잘하는 사람들은 빈칸에 들어갈 말로 ‘이불’이 적합하다는 것을 어렵지 않게 유추할 수 있다. 매우 익숙한 단어의 시퀀스이기 때문이다. 실제로 검색해보면, 이불이 많이 걸린다.
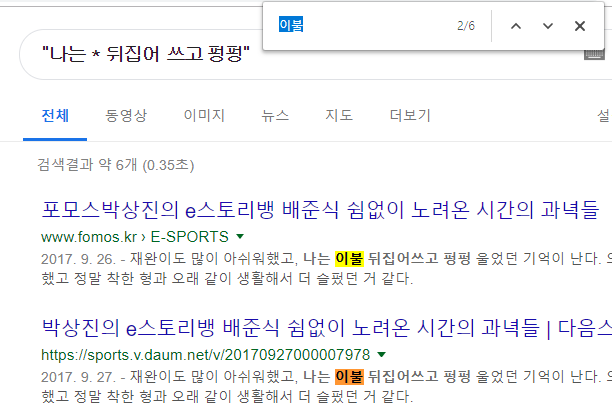
구글 검색결과
위와 같이, 해당 언어를 자유자재로 구사하는 사람은 특정 단어가 자주 사용되는 문맥에서 해당 단어를 제외시켰을 때에도 지워진 단어를 쉽게 유추할 수 있다. 이 점을 이용한 것이 빈칸추론 문제이다. 해당 언어에 능통한 사람만이 풀 수 있는 문제이기 때문이다.
기계학습 관점에서 바라본 빈칸 추론 문제
빈칸추론 문제 지문에서 자주 사용되는 표현 중에 이런 문구가 있다. “다음 빈칸에 들어갈 말로 자연스러운 단어/표현은?” 고등학생 때, 이 자연스럽다라는 표현만큼 애매한게 없었다. 그래서 나는 언어, 외국어 성적이 낮았음 ^^
지금 생각해보면, 자연스럽다라는 것은 아마 “해당 언어에 능통한 사람들이 자주 사용하는 언어패턴에 비추어볼 때 크게 어긋나지않고 문맥 흐름을 훼손하지 않는” 정도로 이해할 수 있을 듯하다. 그런데 곰곰히 살펴보니, 이 관점은 기계학습의 Prediction 문제와 매우 닮아있다. 만약, 아래 그림처럼 빈칸이 뚫린 문맥을 입력으로 받고 그 빈칸에 들어갈만한 단어를 맞추는 (즉, 예측하는) 모델을 구축하면 어떨까? 문맥 데이터를 대량으로 학습한다면, 이 모델은 왠지 나보다 빈칸 추론 문제를 더 잘 풀 것 같다.
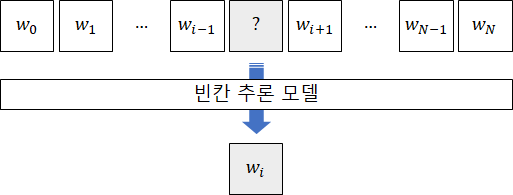
이렇게 학습된 빈칸 추론 모델이 만일 사람보다, 또는 사람만큼 빈칸 추론 문제를 잘 푼다고 가정해보자. 단, 문맥에 대한 완벽한 이해를 요구하는, 즉 수능형 빈칸 추론 문제 말고, 그냥 단순한 단어 사용 패턴 (상용구나 숙어 위주의) 문제로 한정시키자. 그렇다면 적어도 이 빈칸 추론 모델은 단어 사용 패턴에 있어서는 사람만큼의 지식을 갖추고있다고 볼 수 있지 않을까?
Word2Vec란?
개인적인 추축으로는 Word2Vec는 이러한 고찰에서 시작되지 않았나 싶다. 이 논문은 동일 저자의 논문인
Mikolov, Tomas, et al. “Efficient estimation of word representations in vector space.” arXiv preprint arXiv:1301.3781 (2013).
을 발전시킨 것인데, 원 논문에서는 Word Representation을 위한 두 가지 모델을 제안하였다. CBoW(Continuous Bag of Words) 모델과 Skip-gram 모델이 그것인데, 본 포스트에서는 SKip-gram을 위주로 다룬다.
2020 저자 주: 다룬다고 하고 안다루는 글이 너무 많네요 죄송합니다. 제꺼보다 더 잘 쓴 블로그를 첨부합니다 ^^;
https://dreamgonfly.github.io/blog/word2vec-explained/