(미완) Deep Learning 기반 음원분리 튜토리얼 (Deep Learning-basessd Source Separation Tutorial)
24 Oct 2020이번 포스트에서는 딥러닝 기반 음원분리 기법을 다룬다.
얼마 전, 2020년도 국제음악정보검색학회 (ISMIR2020)에서
Source Separation 기법을 발표한 적이 있다.
생각보다 질의응답한 내용이 많아서 정리할 겸 튜토리얼 포스트를 적는다.
Task Definition: Source Separation
음원분리 (Source Separation) 이란 여러 음원이 섞인 음성신호 (음악파일 등)에서 원하는 소리만 분리하고 싶을 때 사용할 수 있는 기법이다.
아래는 이번 ISMIR2020에서 발표할 때 사용하였던 U-Nets with TFC-TDFs (large) 모델을 사용하여 “폴킴 - 허전해” 곡의 보컬을 분리한 결과이다.
Example: 폴킴의 허전해 음원분리 예제
그렇다면 음원분리를 어떻게 접근해야 할까?
아래 예제는 고음역대를 filtering 해줌으로써 저음역대의 악기 (kick drum + bass) 만 남기는 예제이다.
근데 10년 전만해도 다들 이렇게 했던 것 같은데, 요즘은 그냥 izotope같은 회사에서 나온 괴물같은 소프트웨어 돌리면 기가막히게 음원 뽑아준다. 그러고보니 이번 ISMIR2020 학회에 izotope 연구원이 오셔서 논문도 발표했다. Singing Voice Conversion이 주제였는데 열심히 듣긴했는데 다 까먹었다. )
이러한 원리를 조금 더 확장시켜보면, 내가 원하는 악기가 있을만한 주파수대만 남기고 다른 주파수는 filtering 함으로써 음원분리를 수행할 수 있지 않을까하는 생각이 든다.
-
다만 약간의 걸림돌이 있다면
-
위 예제처럼 kick drum과 bass의 경우 다른 악기와 잘 겹치지 않는 저음역대라 분리가 쉽지만
-
보컬, 피아노, 그리고 기타 같은 세 악기는 음역대가 많이 겹치는 편이라
-
위 예제같이 시간대에 상관없는 static한 주파수 filtering을 이용하면 곤란하다.
-
-
이를 통해 얻을 수 있는 결론:
- TLDR: 주파수 기반의 음원 분리를 하려거든, 노래를 들어보고, 내가 조져야 할 주파수를 타게팅한뒤, 나머지 주파수를 조져야 한다.
Spectrogram: 컴퓨터에게 소리의 높낮음 가르치기
그런데 또 한가지 걸림돌이 되는 것이 있다.
- 우리는 달팽이관의 캐리로 음악을 듣는 즉시 주파수가 분리가 된다.
- 아 높다, 아 낮다, 아 섞였다 등을 감지
- 나같은 막귀도 아 이 지점에서 피아노와 보컬이 같이 나오는구나 쯤은 알 수 있다.
- 그러나 컴퓨터에게 소리는 그저 시간의 흐름에 따라 값이 달라지는 숫자의 연속 신호일 뿐이다.
- 컴퓨터는 소리 신호만 듣고 이것의 높고 낮음 따위는 인지하지 못한다.
- 즉, 컴퓨터에게는 주파수 정보가 없다.
-
이럴 때 사용하는 방법이 Spectrogram이다.
-
Spectrogram을 완전히 이해하기 위해서는 Fourier Transform을(tutorial 1, tutorial 2)에 대해 먼저 알아야한다.
-
그러나 그거 설명하는 건 배보다 배꼽이 크므로 쿨하게 스킵하되, 무슨 역할을 하는지만 알아보자.
-
TLDR: Fourier Analysis
- 시간에 따라 변화하는 값인 신호정보를 주파수 형식으로 바꿔줌
-
-
Q. 오 그러면 3분짜리 음악에 통으로 Fourier Transform을 적용하면 되나요?
A. 아아. 곤란.
- 이유
- 통으로 Fourier Analysis를 적용하면 시간정보가 아예 날라남. 적어도 ‘어디에서’ 사람목소리가 발견되었는지는 알아야하지않는가? 더보기
- 어차피 44100Hz (1초에 44100번의진동) 을 넘어가면 가청주파수를 벗어난다. 분석한 주파수의 대다수는 돌고래조차 못듣는다.
- 대안: Short-time Fourier Transform (STFT)
- 따라서 작은 window size (일반적으로 <= 4096) 만큼의 샘플에 대해서만 Fourier Transform을 적용하여 이 window에 대한 주파수를 분석하고 다음 window로 이동해서 이 짓을 반복하는 Short-time Fourier Transform (STFT)을 사용한다.
- STFT에 대한 주피터 노트북 세미나 자료 by 김진성
- STFT를 음악파일에 적용하면 이렇게 생긴게 나오는데, 이를 Spectrogram이라고 한다.
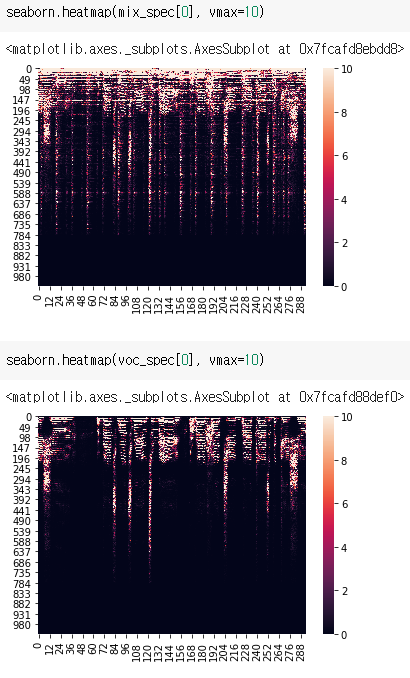
- 위 그림이 원본 음악에 대한 Spectrogram
- 아래 그림이 보컬에 대한 Spectrogram
- 따라서 작은 window size (일반적으로 <= 4096) 만큼의 샘플에 대해서만 Fourier Transform을 적용하여 이 window에 대한 주파수를 분석하고 다음 window로 이동해서 이 짓을 반복하는 Short-time Fourier Transform (STFT)을 사용한다.
Spectrogram 기반 음원분리
이제 시간에 따라 높낮이가 어떻게 변화하는지에 대한 정보도 탑재된 인풋과 아웃풋 페어가 준비되었다.
이제 딥러닝적 마인드로 돌아와서, 다음과 같은 입출력을 가지는 신경망을 학습했다고 가정해보자.
입출력
- 입력: 원본 음악에 대한 Spectrogram \(M\)
- 출력: 보컬에 대한 Spectrogram \(T\)
음원분리 신경망: inference
그렇다면 이 신경망은 다음과 같은 프로세스로 음원분리를 수행할 수 있다.
- 임의의 혼합 음원 \(M_{audio}\)를 입력받아
- STFT를 이용하여 스펙트로그램 \(M\)을 추출
- 잘 훌련된 보컬 스펙트로그램 추출 신경망 \(net\)으로 \(\hat{T} = net(M)\) 예측
- \(\hat{T}\)에 iSTFT (STFT의 역연산)을 적용하여 오디오 신호 \(\hat{T}_{audio}\)를 추출
- \(\hat{T}_{audio}\)는 보컬만 있는 음원!
음원분리 신경망: training
이러한 신경망은 다음과 같은 방법으로 학습시킬 수 있다.
그렇다면 이 신경망은 다음과 같은 프로세스로 음원분리를 수행할 수 있다.
- epoch 시작
- 학습데이터에서 주어진 혼합 음원과 대응되는 보컬 음원 \(M_{audio}, T_{audio}\)에 대해
- STFT를 이용하여 스펙트로그램 \(M, T\)을 추출
- 신경망 \(net\)으로 \(\hat{T} = net(M)\) 예측
- \(loss(\hat{T}, T)\)를 최소화하는 방향으로 망 학습!
- epoch 종료조건 미달 => 1로 이동