Paper Review: A Neural Probabilistic Language Model
21 Dec 2018최근 작성한 포스트에서 “Distributed Representation은 왜 필요한가? (중략) 전통적인 NLP 기법은 차원의 저주 문제가 발생한다고 한다. [7]번 논문에서 설명되어있다는데… “라고 언급한 적이 있다. 본포스트에서는 문제의 [7]번 논문
Bengio, Yoshua, et al. “A neural probabilistic language model.” Journal of machine learning research 3.Feb (2003): 1137-1155.
를 읽어보고 차원의 저주 문제와 Distributed Representation에 대해 고찰해보고자 한다.
Preliminaries: 본 논문을 이해하기 위해서 알고 있어야하는 지식
Statistical language modeling의 목적은 단어들의 배열(sequence)에 대한 joint probability function을 학습하는 것이다.
수업에서 들어서 대충은 알고 있는 내용인데, 내가 알기로는 이 진술에 대한 글을 작성하려면 포스트 하나만으로 안끝난다. 일단은 받아드리고 시작하자.
Curse of dimensionality in Statistical Language Modeling
Statistical language modeling의 목적은 단어들의 배열(sequence)에 대한 joint probability function을 학습하는 것이다. 그런데, 이 목표를 달성하는게 무지하게 어렵다. 차원의 저주가 발생하기 때문이다. 차원의 저주란 고차원 공간에서 데이터를 다룰 때 나타나는 성능 저하 현상을 이르는 용어이다. 그렇다면 Statistical Language Modeling에서 차원의 저주는 왜 발생하는가? 차근차근 알아보자.
왜 고차원 공간인가?
통계적으로 언어를 모델링하기 위해서는 먼저 단어와 문장에 대한 모델링이 필요하다. 가장 심플한 방법으로는 단어 하나하나마다 별도의 차원을 할당하여 문장을 벡터화 시키는 것이다. 이를 Bag of Words 모델이라고 부른다. 우리가 사용하는 한국어 단어의 수는 대략 498,867개이므로, 약 50만개의 차원으로 문장이 모델링된다고 볼 수 있다. 만약 n-gram 모델로 문장을 표현한다면, 각 문장은 50만개^n 차원으로 표현된다.
무슨 문제가 발생하는가? (1) Data scarcity 문제 - 관찰한 데이터와 테스트 데이터간의 괴리
Statistical Language Modeling은 사실 원래 어렵다. 이 모델링에서의 최종 목적은 단어의 배열에 대한 joint probability를 계산할 수 있는 function을 만드는 것이다.
문제는 관찰한 데이터 (training data) 집합과 훈련 후 마주하는 테스트 데이터 (test data) 간에 괴리가 생긴다는 것이다. 예를 들어 데이터 학습을 빡세게 했다고 치자. 그렇다면 “예를 들어 데이터 학습을 빡세게 했다고 치자”라는 문장을 구글에 검색하면, 정확하게 일치하는 문장이 나올까?
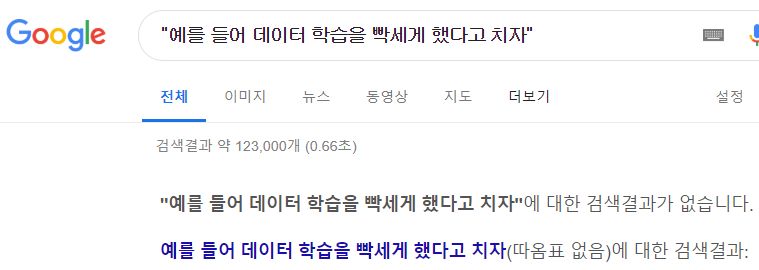
예제 검색
안나온다. 구글이 training 한 데이터에 저 문장과 정확히 일치하는 문장이 없었기 때문이다. 50만개의 단어로 생성할 수 있는 문장의 수는 무한하기 때문에 애초에 정확하게 일치하는 문장을 찾는 것은 당연하게도 매우 어렵다. 문장의 길이가 길면 길수록 어렵다. 이런 문제는 Data scarcity (데이터 부족) 문제라고 한다.
무슨 문제가 발생하는가? (2) 파라미터 낭비 문제
Bag of Words 모델을 기반으로, 문장 s를 498,867차원의 한 벡터 BoW(s)로 표현해보자. 각 차원에 해당하는 단어가 문장에서 사용된 횟수를 계산하여 값을 할당해보자. 문장에서 20개의 서로 다른 단어가 s에서 사용되었다면, 0이 아닌 값을 가지는 차원의 수는 498,847 (=498,867-20) 개 일 것이다. 이 20개의 단어로 이루어진 문장을 표현을 위해 20개의 차원만 일하고, 나머지 498,847개의 차원은 놀고 있다. 즉, 파라미터는 많아서 계산량 많고 힘들어 죽겠는데 대부분은 놀고 있는 친구들이다.
무슨 문제가 발생하는가? (3) Discrete 표현 상의 문제
기본적으로 tf-idf 같은 고급 모델이 아닌 이상, Bag of Words 모델이나 n-gram 모델은 count-based로 벡터화 한다. 즉 단어가 얼마나 사용되었는지 그 횟수를 측정한다. 그렇기 때문에 모든 차원의 값이 정수로 표현된다.
직관적으로 생각해보면, 이는 큰 제약 조건이 된다. 소묘할 때 연필이 연속적으로 움직이지 않고 뚝뚝 떨어져서 움직인다면 정교하게 대상을 묘사할 수 있겠는가? discrete한 표현은 continuous한 표현보다 분명한 한계를 가질 것이다.
논문에서는 discrete한 표현법이 “일반화 능력이 떨어지기 때문에” 좋지않다라고 표현했다. 즉 한차원의 값이 조금만 바뀌어도 모델은 비교적 큰 영향을 받게된다. 그렇기 때문에 이미 관찰한 문장들 자체가 지들끼리 멀리 떨어져서 위치하게 된다.
무슨 문제가 발생하는가? (4) 유사성 희석 문제 (개인적인 추측)
논문에서 다루지는 않았으나, 개인적인 추측이 담겨있어서 틀릴 수도 있으므로 주의!
기본적으로 이러한 기법들이 단어나 문장, 문서를 벡터화할 때 암묵적으로 추구하는 성질이 있다. 바로 서로 다른 비슷한 두 문장을 벡터화하면, 이 벡터들은 서로 유사성이 높아야한다는 점이다. (그런데 논문을 읽어가면서 느낀건데, 이러한 암묵적 성질은 이 논문 이후에 보편화된것일지도 모른다.)
이러한 성질은, 단어나 문장, 문서가 맵핑되는 공간이 고차원일수록 또 continuous하지 않을 수록 불리하다. 당연하게도 차원이 늘어나면 늘어날 수록 벡터간의 간격은 늘어나면 늘어나지 줄어들지는 않는다. 거기다가 discrete하다면 더 늘어날 것이다. 유사하지 않은 문장이 벡터화 되었을 때의 거리가 늘어나는건 상관이 없다. 문제는 서로 유사한 문장도 벡터화 되었을 때 멀리 떨어져서 위치하게 된다.
이는 결국 벡터 공간으로 매핑된 단어나 문장 간의 유사성을 기반으로 구축된 모든 시스템들의 성능을 떨어뜨리게 만드는 아킬레스건으로 작용한다. 말투 현학적인듯. 음 그러니까 고차원으로 갈 수록 유사해야하는 대상들간의 유사성마저 희석되는 것이 문제라고 볼 수 있다. 더 현학적인듯.
기존 기법들의 단점은 무엇인가?
차원의 저주를 피하기 위한 다양한 연구들이 진행되었다. 그러나 이 논문에서 지적하는 기존 기법들의 문제는 다음과 같이 요약할 수 있다.
- 문맥을 모델링할 때 단어 한 두개 이상 고려하지 않는다.
- 단어의 유사성에 대해 고려하지 않는다.
1번 지적은 사실 안하는게 아니라 못하는 것에 가깝다. 일단 이를 설명하려면 Statistical Language Model과 n-gram에 대한 설명이 필요한데, 이는 나중에 다른 포스트에서 따로 설명하겠다. 큰 줄기만 요약하여 설명하자면, 다음과 같다.
기존연구 문제점 1: 문맥을 모델링할 때 단어 한 두개 이상 고려하지 않는다.
Statistical Language Model이 궁극적으로 추구하는 것은 주어진 임의의 문맥 S을 관찰할 확률 P(S)를 모델링하는 것이다. 이때, 문맥 S는 단어의 시퀀스 (S=w1,w2,...,wm)로 정의된다고 가정해보자. 즉,
으로 표현 가능하다. 이 확률을 풀어 쓰면 다음과 같은 조건부 확률의 chain으로 표현할 수 있다.
\[P(S) = P(w_{1})\times P(w_{2}|w_{1})\times P(w_{3}|w_{1},w_{2}) \times ... \times P(w_{m} | w_{1},w_{2},...,w_{m-1})\]이를 더 간추려서 표현하면,
\[P(S) = \prod_{i=1}^{m}{P(w_{i}|w_{1},w_{2},...,w_{i-1})}\]과 같다.
학부생 때 수업에서 이걸 봤을 때는 정신이 혼미해졌는데, 별거 아닌 것 같다. 다음과 같이 이해할 수 있다.
내가 멍때리고 있다가 갑자기 정신 차렸을 때 들린 문장이 “다음과 같이 이해할 수 있다” 일 확률 = 처음 들린 단어가 “다음과” 였을 확률 x “다음과” 다음에 “같이”가 나올 확률 x “다음과 같이” 뒤에 “이해할” 이 나올 확률 x “다음과 같이 이해할” 다음에 “수”가 나올 확률 x “다음과 같이 이해할 수” 다음에 “있다로 문장이 종결될 확률과 같다.
문제는 위에도 서술되었듯, “관찰한 데이터와 테스트 데이터간의 괴리” 문제로 인해 데이터를 많이 아무리 많이 확보해도 실전에서는 듣지도 보지도 못한 새로운 문장을 맞딱뜨리게 된다는 점이다. 이 문장을 구성하는 시퀀스를 트레이닝 데이터셋에서 직접적으로 유추할 수 없기에 굉장히 난감해진다.
예를 들어 “다음과 같이 이해할 수 있다”라는 문장이 발견될 확률을 구하기 위해서는 “다음과 같이 이해할 수” 다음에 “있다”라는 단어가 나올 확률이 필요하다. 그런데 이 확률을 트레이닝 데이터 셋에서 추정해내기가 어렵다. “다음과 같이 이해할 수”라는 조합 자체가 나오는 경우가 굉장히 희귀하기 때문이다. 문장이 길면 길어질 수록, 이 확률을 데이터 셋에서 직접적으로 추정해 내는 것은 불가능에 가깝다.
이러한 문제를 해결하기 위한 절충안으로 n-gram 모델이 사용되어 왔다. n-gram 모델에서는 이 확률을 다음과 같이 근사(approximate)한다.
\[P(S) = \prod_{i=1}^{m}{P(w_{i}|w_{1},w_{2},...,w_{i-1})} \approx \prod_{i=1}^{m}{P(w_{i}|w_{i-(n-1)},w_{i-(n-2)},...,w_{i-1})}\]n-gram에서 사용하는 핵심 가정은 다음과 같다.
\[{P(w_{i}|w_{1},w_{2},...,w_{i-1})} \approx {P(w_{i}|w_{i-(n-1)},w_{i-(n-2)},...,w_{i-1})}\]즉, 원래는 첫단어부터 i-1개의 단어가 나온 후 wi가 나올 확률을 구해야하는데, 그건 데이터도 없고 귀★찮★으니까 아아 됐고 사장님 저 마지막 n개 까지만 볼게요 수고하세요 하는 것이다. 이게 실전에서 먹힐거라고 생각했는지 ㅋㅋ

Claude Shannon: 되는데요?
잘된다고합니다. ㄷㄷ…
그래서 딥러닝 붐이 일기 전까지의 Statistical Language Model은 n-gram의 영향력이 엄청났다고 한다. 아무튼 2-gram (바이그램, bi-gram) 모델에서는 P("있다"| "다음과 같이 이해할 수") 를 P("있다"|"이해할 수") 로 근사한다. 후자는 데이터 확보가 가능한 편이니까. 뭐 그래도 확보할 수 없는 케이스가 발생하기는 하는데, 이건 smoothing 기법 등의 추가적인 방법으로 무마한다.
그럼에도 불구하고 또 무슨 문제가 있느냐? 일반적으로 사용되는 n-gram 모델로는 1-gram, 2-gram, 3-gram 모델 이 있다. 이 논문에 따르면 5-gram 기반의 논문도 있다고는 하는데, 이 경우 대부분 data scarcity 문제 때문에 별로라고 한다.
기존연구 문제점 2: 단어의 유사성에 대해 고려하지 않음
전통적인 Statistical Language Modeling 기법들은 말 그대로 트레이닝 데이터에서 문장 또는 단어가 발견될 확률을 통계적으로 추정한다. 이를테면
\[{P(w_{i}|w_{1},w_{2},...,w_{i-1})} = \frac{count(w_{1},w_{2},...,w_{i-1},w_{i})} {count(w_{1},w_{2},...,w_{i-1})}\]와 같이 표현된다. (출처: Wikipedia)
그런데 이 과정에서 단어간의 유사성은 전혀 고려되지 않는다. 논문의 예제(S1, S2)와 임의로 만들어본 예제 문장(S3)을 살펴보자.
S1: The cat is walking in the bedroom.
S2: A dog was running in a room.
S3: A soldier shouted “Fire in the hole!”
다음과 같은 관점에서 사람이 보기에는 S1과 S2는 매우 유사한 문장이다.
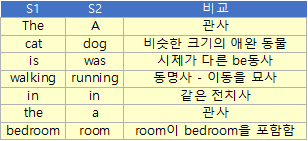
그런데 이 문장들을 벡터화 시켜보자. 간단하게 16차원의 uni-gram으로만 표현해보자.

이렇게 얻은 벡터를 이용하여 코사인 유사도를 계산해보면
S1과S2의 유사도는0.38S1과S3의 유사도는0.43S2과S3의 유사도는0.38로
세 문장 중 가장 유사한 두 문장 pair는 S1과 S3가 된다.
비직관적인 결론이 도출된데에는 여러 이유가 있겠지만, 무엇보다 단어간의 유사성이 고려되지 못한 탓이 크다. S1과 S2에서 사용되는 단어는 적어도 형태소적으로 같은 역할을 수행하지만, 전통적 Statistical Language Model에서는 이러한 단어의 유사성이 고려되지 않는다.
아직 와닿지 않는 다면 다음 사실은 어떤가? 단어 하나만 벡터화해보자.
- The와 dog의 유사도는 0이다. (완전 다름)
- dog와 cat의 유사도는 0이다. (완전 다름)
- is와 was의 유사도도 0이다. (완전 다름)
- is와 is의 유사도는 1이다. (완전 같음)
위에서 알 수 있는 사실은, 같은 단어가 아닌 이상 얄짤없이 완전다르다고 평가해버린다는 사실이다. 따라서 dog와 cat이 유사하다는 (적어도 우리에게 친숙한 애완동물이라는 관점에서 유사하다는) 정보가 완전하게 소실된다.
차원의 저주 뚜까패기: 신경망 기반의 Distributed Representation
기존 연구에는 두 가지 문제점이 있다고 하였다.
- 문맥을 모델링할 때 단어 한 두개 이상 고려하지 않는다.
- 단어의 유사성에 대해 고려하지 않는다.
(그런데 그 기존연구라는게 2003년 시점에서의 기존 연구라는 것이 함정)
이 기존연구의 문제점을 해결하고자 많은 기법들이 제안되어 왔다고 한다. 즉, 즉 기존연구를 보안하기 위한 기존연구들. 이들은 1.2장에 요약되어있다는데, 나중에 읽을 것이다. 사실 안읽을 것이다.
어쨋든 이 논문은 문제를 근본적으로 타파하기 위해 다소 모험적인 시도를 한듯하다.
전통적인 Statistical Language Model에서 탈피한 신경망 기반의 Probabilistic Language Model을 제안한 것이다.