Logistic Regression으로 And Gate 만들어보기 (Python + Numply code)
03 Jan 2019이 포스트에서는 Logistic Regression 모델로 And Gate를 만들어본다.
이론적 배경은 이 포스트에 정리해놓았으니 필요하신 분들은 참조!
먼저 데이터를 만들어보자.
데이터 만들기
우리가 만들 데이터는 다음과 같은 데이터이다.
| \(i\) | \(x_{i}=(x_{0i}, x_{1i})\) | \(y_{i}\) |
|---|---|---|
| \(0\) | \((0,0)\) | \(0\) |
| \(1\) | \((0,1)\) | \(0\) |
| \(2\) | \((1,0)\) | \(0\) |
| \(3\) | \((1,1)\) | \(1\) |
import numpy as np
x0 = np.array([0, 0]).reshape((2,1))
x1 = np.array([0, 1]).reshape((2,1))
x2 = np.array([1, 0]).reshape((2,1))
x3 = np.array([1, 1]).reshape((2,1))
y0 = 0
y1 = 0
y2 = 0
y3 = 1
모델 구조
모델은 블로그 포스트에 나와있는 모델을 그대로 쓸 것이다.

모델을 행렬 식으로 나타내보자.
우선, 파라미터가 \(W = \begin{bmatrix} w_{0} \\ w_{1} \end{bmatrix}\), \(b\) 로 정의되어 있을 때, Logistic regression 모델의 prediction 값은 \(\hat{y} = \sigma (W^{T}x+b)\) 로 정의된다.
조금 친절하게 표기하자면, \(o= W^{T}x+b = \begin{bmatrix} w_{0} & w_{1} \end{bmatrix} \begin{bmatrix} x_{0} \\ x_{1} \end{bmatrix}+b = w_{0}x_{0} + w_{1}x_{1} + b\) \(z = \sigma (o)\) \(\hat{y} = z\)
이다.
파라미터 초기화
파라미터들은 다음과 같이 간단하게 0으로 초기화해주자.
def init_parameters ():
W = np.zeros((2,1))
b = 0.
return W, b
W, b = init_parameters()
print (W)
print (b)
[[0.]
[0.]]
0.0
Forward processing
이제 주어진 파라미터 \(W, b\)를 가지고 \(\hat{y}\)를 산출하는 코드를 만들어보자.
def sigmoid (o):
return 1./(1+np.exp(-o))
def forward (W, x, b):
z = sigmoid(np.dot(W.T, x) + b)
return z
print(forward(W, x0, b))
print(forward(W, x1, b))
print(forward(W, x2, b))
print(forward(W, x3, b))
[[0.5]]
[[0.5]]
[[0.5]]
[[0.5]]
Cost Evaluation
이번에는 현재 파라미터의 cost가 어느정도인지 계산하는 함수를 만들어보자.
def cost_eval (W,b):
test_set = [
[x0, y0],
[x1, y1],
[x2, y2],
[x3, y3]
]
loss = 0
for test_example in test_set:
x = test_example[0]
y = test_example[1]
y_hat = forward(W, x, b)
loss = loss - (y*np.log(y_hat) + (1-y)*np.log(1-y_hat))[0]
return loss
현재 0으로 초기화된 파라미터의 코스트를 계산해보자.
print(cost_eval(W,b))
[2.77258872]
Parameter Optimization with Gradient Descent
이제 Gradient Descent을 이용해서 파라미터를 최적화시켜보자.
\[\frac{d \mathcal{L}}{dW} = \begin{bmatrix} dw_{0} \\ dw_{1} \end{bmatrix} = \begin{bmatrix} (z-y)x_{0} \\ (z-y)x_{1} \end{bmatrix}\]임을 기억해보자 (이론은 이곳 참조). 이를 간단하게 표현하면 \(\frac{d \mathcal{L}}{dW} = (z-y) \begin{bmatrix} x_{0} \\ x_{1} \end{bmatrix} = (z-y)x\) 이다.
\(b\)의 경우 \(\frac{d \mathcal{L}}{db} = z-y\) 이다.
note: 코드에서는 \(\frac{d \mathcal{L}}{dW}\) 를 간단하게 \(dW\)로, \(\frac{d \mathcal{L}}{db}\)를 간단하게 \(db\)로 쓰겠다. Gradient Descent 방법을 이용하여 파라미터를 튜닝시켜보자. 이때 learning rate은 0.01로 하고, epoch는 10000번으로 해보자.
def gradient_descent (W,b,learnig_rate = 0.01, iteration = 10000):
costs = []
training_set = [
[x0, y0],
[x1, y1],
[x2, y2],
[x3, y3]
]
for epoch in range(iteration):
dW = np.zeros((2,1))
db = 0
for training_example in training_set:
x = training_example[0]
y = training_example[1]
z = forward(W, x, b)
dW = dW + (z-y)*x
db = db + (z-y)
W = W - learnig_rate * dW
b = b - learnig_rate * db
costs.append(cost_eval(W,b))
return W, b, costs
gradient_descent 함수는 (x0, y0), (x1, y1), (x2, y2), (x3, y3) 네 개의 트레이닝 데이터를 학습하여 파라미터 W, b를 Gradient descent 방법으로 최적화하는 함수다. 0으로 초기화한 파라미터를 입력으로 하여 돌려보자.
W, b = init_parameters()
W_new, b_new, costs = gradient_descent(W,b)
잘 학습되었는지 확인해보기
먼저 Cost가 어떻게 변하는지 보자.
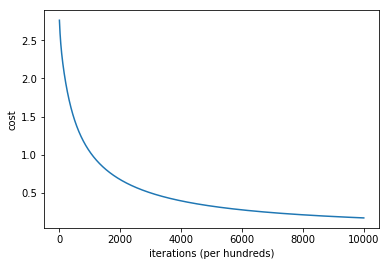
import matplotlib.pyplot as plt
plt.plot(costs)
plt.ylabel('cost')
plt.xlabel('iterations (per hundreds)')
plt.show()
<Figure size 640x480 with 1 Axes>
일관적으로 줄어드는 것을 잘 확인했다. 다음으로는 직접 \(x_{i}\)에 대한 \(\hat{y_{i}}\) 값을 예측해보자.
print (forward(W_new, x0, b_new))
print (forward(W_new, x1, b_new))
print (forward(W_new, x2, b_new))
print (forward(W_new, x3, b_new))
[[0.00019724]]
[[0.0491068]]
[[0.0491068]]
[[0.93112344]]
잘 학습된 듯 하다.
Advanced: 행렬(Matrix) 연산으로 바꾸기
위에서 처럼 for loop을 사용하는 것보다는 가급적 행렬 연산으로 표현하는 것이 더 좋다. CPU를 사용하든 GPU를 사용하든, 요즘은 행렬 연산에 대한 병렬화가 잘 되어있기 때문에 가급적 for loop을 없애는 노력이 필요하다. for loop 자체를 없애지는 못하더라도 반복 횟수를 줄이는 방법도 있다 (e.g. Mini batch).
그렇다면 어떻게 행렬 연산으로 for loop을 없앨까?
먼저 데이터 셋부터 다음과 같이 행렬 형태로 나타내보자.
\[X = \begin{bmatrix} x_{0} & x_{1} & x_{2} & x_{3} \end{bmatrix} = \begin{bmatrix} x_{00} & x_{01} & x_{02} & x_{03} \\ x_{10} & x_{11} & x_{12} & x_{13} \\ \end{bmatrix} = \begin{bmatrix} 0 & 0 & 1 & 1 \\ 0 & 1 & 0 & 1 \\ \end{bmatrix}\] \[Y = \begin{bmatrix} y_{0} & y_{1} & y_{2} & y_{3} \end{bmatrix} = \begin{bmatrix} 0 & 0 & 0 & 1 \end{bmatrix}\]이는 numpy 라이브러리를 이용해서 다음과 같이 표현할 수 있다.
X = np.hstack((x0, x1, x2, x3))
print('X = ')
print (X)
print('X\'s shape = ' + str(X.shape))
Y = np.hstack((y0, y1, y2, y3)).reshape(1,4)
print('Y = ')
print (Y)
print('Y\'s shape = ' + str(Y.shape))
X =
[[0 0 1 1]
[0 1 0 1]]
X's shape = (2, 4)
Y =
[[0 0 0 1]]
Y's shape = (1, 4)
이렇게 바꾸면, 행렬 연산에 의해 다음과 같이 4개의 \(o_i\)를 한꺼번에 구할 수 있다.
\[\begin{aligned} O &= \begin{bmatrix} o_{0} & o_{1} & o_{2} & o_{3} \end{bmatrix} \\ &= \begin{bmatrix} W^{T}x_{0} + b & W^{T}x_{1} + b & W^{T}x_{2} + b & W^{T}x_{3} + b \end{bmatrix} \\ &= W^T \begin{bmatrix} x_{0} & x_{1} & x_{2} & x_{3} \end{bmatrix} + \begin{bmatrix} b & b & b & b \end{bmatrix} \\ &= W^TX + \begin{bmatrix} b & b & b & b \end{bmatrix} \end{aligned}\]이를 이용하면, 4개의 \(\hat{y_i}\) 또한 한 번에 구할 수 있다. \(\begin{aligned} \hat{Y}= \begin{bmatrix} \hat{y_{0)}} & \hat{y_{1}} & \hat{y_{2}} & \hat{y_{3}} \end{bmatrix} = \begin{bmatrix} \sigma(o_{0}) & \sigma(o_{1}) & \sigma(o_{2}) & \sigma(o_{3}) \end{bmatrix} = \sigma (O) \end{aligned}\)
(단, 이때의 \(\sigma\)는 행렬 안의 모든 element에 대해 시그모이드를 취해주는 함수)
이를 numpy 라이브러리를 이용하여 간단하게 표현해보자.
O = np.dot(W.T, X) + b
Z = sigmoid(O)
print(Z)
[[0.5 0.5 0.5 0.5]]
마찬가지로 \(dW\)와 \(db\)를 행렬연산으로 구해보자.
print((Z-Y)*X)
dW = np.sum((Z-Y)*X, axis=1, keepdims = True)
print(dW)
print (Z-Y)
db = np.sum((Z-Y), axis=1, keepdims = True)
print(db)
[[ 0. 0. 0.5 -0.5]
[ 0. 0.5 0. -0.5]]
[[0.]
[0.]]
[[ 0.5 0.5 0.5 -0.5]]
[[1.]]
def gradient_descent_matrix (W,b,learnig_rate = 0.01, iteration = 10000):
costs = []
for epoch in range(iteration):
O = np.dot(W.T, X) + b
Z = sigmoid(O)
dW = np.sum((Z-Y)*X, axis=1, keepdims = True)
db = np.sum((Z-Y), axis=1, keepdims = True)
W = W - learnig_rate * dW
b = b - learnig_rate * db
costs.append(cost_eval(W,b))
return W, b, costs
위처럼 행렬 연산으로 바꾼 버전을 돌려보면, 아까와 똑같은 결과가 나오는 걸 확인할 수 있다.
W, b = init_parameters()
W_new2, b_new2, costs2 = gradient_descent_matrix(W,b)
# Plot learning curve (with costs)
plt.plot(costs2)
plt.ylabel('cost')
plt.xlabel('iterations (per hundreds)')
plt.show()
속도 차이는 얼마나 날까?
import time
tic = time.process_time()
W, b = init_parameters()
W_new2, b_new2, costs2 = gradient_descent_matrix(W,b, 0.01, 10000)
toc = time.process_time()
print ("Matrix Multiplication based \n ----- Computation time = " + str(1000*(toc - tic)) + "ms")
tic = time.process_time()
W, b = init_parameters()
W_new, b_new, costs = gradient_descent(W,b, 0.01, 10000)
toc = time.process_time()
print ("For loop based \n ----- Computation time = " + str(1000*(toc - tic)) + "ms")
Matrix Multiplication based
----- Computation time = 1015.625ms
For loop based
----- Computation time = 1312.5ms
선형 분리기로서의 Logistic Regression
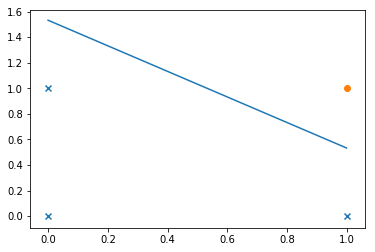
시그모이드가 붙어있다고는 하지만, Logisitic Regression은 어디까지나 선형분리기다. \(o = w_{0}x_{0} + w_{1}x_{1} + b\) 를 자세히 들여다보자. 시그모이드 함수의 성질에 따라 이 값이 0보다 크면 \(1\)로 분류되고, 0보다 작으면 \(\frac{1}{2}\)로 분류된다. \(\hat{y}\)가 1이되기 위한 조건을 부등식으로 나타내면 다음과 같다. \(w_{0}x_{0} + w_{1}x_{1} + b > 0\)
\(x_{0}\)을 2차원 평면 그래프 상의 \(x\)로, \(x_{1}\)을 \(y\)로 나타내보자.
\(y > \frac{-w_{0}}{w_{1}}x - \frac{b}{w_{1}}\) 이다.
이 식의 의미를 보기 위해 그래프를 그려보자.
먼저 데이터부터 표시해보자.
plt.figure()
plt.scatter(X[0,0:3],X[1,0:3], marker='x')
plt.scatter(X[0,3],X[1,3], marker='o')
plt.show()

이제, 선분을 그려보자.
x = np.arange(0, 1, 0.001)
y = []
for t in x:
y.append( float(-W_new[0]/W_new[1]*t - b_new/W_new[1]))
plt.figure()
plt.scatter(X[0,0:3],X[1,0:3], marker='x')
plt.scatter(X[0,3],X[1,3], marker='o')
plt.plot(list(x),list(y))
[<matplotlib.lines.Line2D at 0x1b4dcef7cc0>]